|
|
|
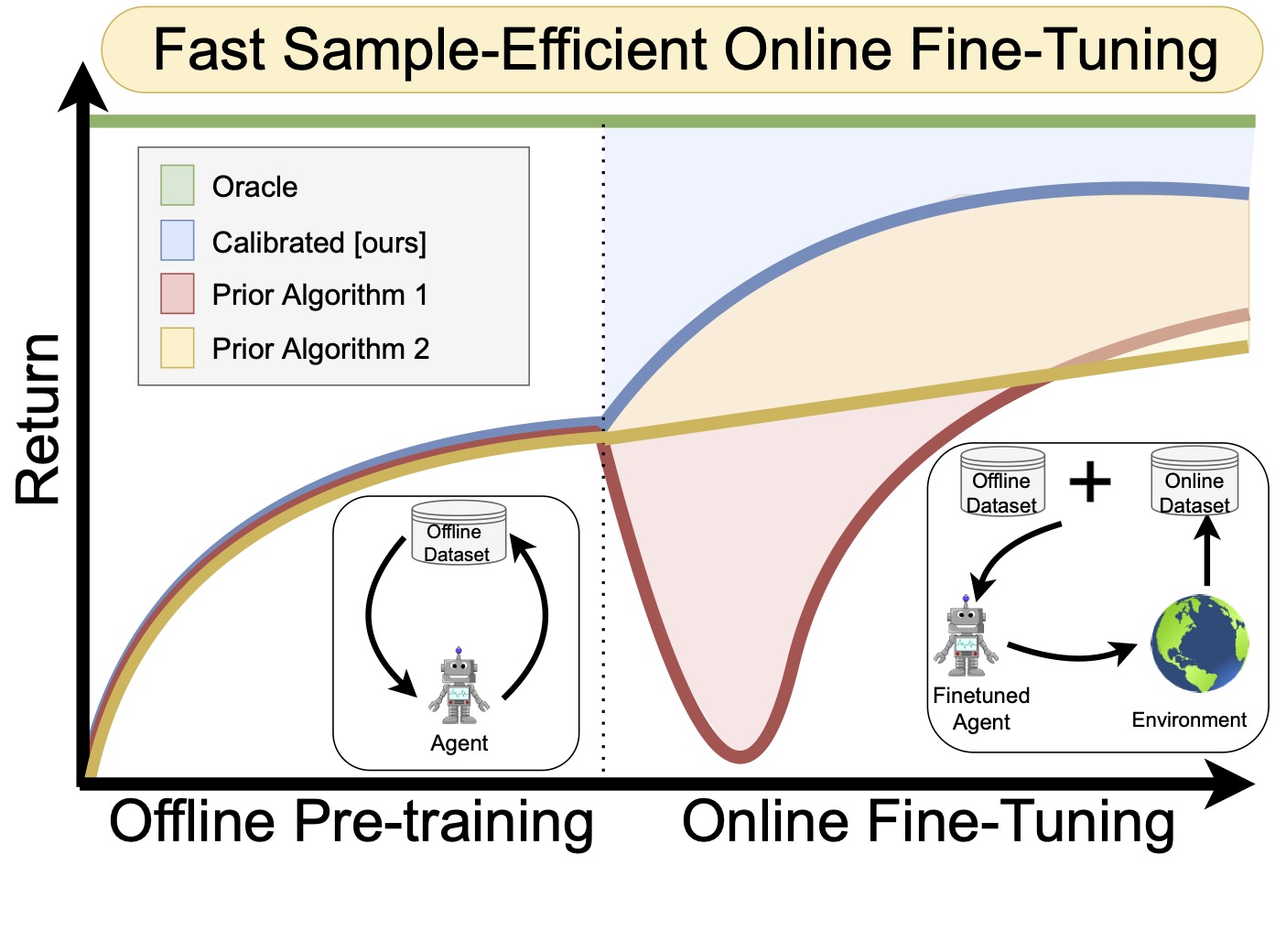
A compelling use case of offline reinforcement learning (RL) is to obtain a policy initialization from existing datasets followed by fast online fine-tuning with limited interaction. However, existing offline RL methods tend to behave poorly during fine-tuning. In this paper, we devise an approach for learning an effective initialization from offline data that also enables fast online fine-tuning capabilities. Our approach, calibrated Q-learning (Cal-QL), accomplishes this by learning a conservative value function initialization that underestimates the value of the learned policy from offline data, while also being calibrated, in the sense that the learned Q-values are at a reasonable scale. We refer to this property as calibration, and define it formally as providing a lower bound on the true value function of the learned policy and an upper bound on the value of some other (suboptimal) reference policy, which may simply be the behavior policy. We show that offline RL algorithms that learn such calibrated value functions lead to effective online fine-tuning, enabling us to take the benefits of offline initializations in online fine-tuning. In practice, Cal-QL can be implemented on top of the conservative Q learning (CQL) for offline RL within a one-line code change. Empirically, Cal-QL outperforms state-of-the-art methods on 9/11 fine-tuning benchmark tasks that we study in this paper.
|
|
How can we devise a method to learn an effective policy initialization that also improves during fine-tuning? Prior methods such as CQL often tend to "unlearn" the policy initialization learned from offline data and waste samples collected via online interaction in recovering this initialization. We find that this sort of a "unlearning" phenomenon is a consequence of the fact that value estimates produced via conservative methods can be significantly lower than the ground-truth return of any valid policy. Having Q-value estimates that do not lie on a similar scale as the return of a valid policy is problematic: once fine-tuning begins, actions executed in the environment for exploration that are actually worse than the policy learned from offline data could erroneously appear better, if their ground-truth return value is larger than the learned conservative value estimate. Hence, subsequent policy improvement will begin to lose the initialization in favor of such a worse policy until the method recovers. 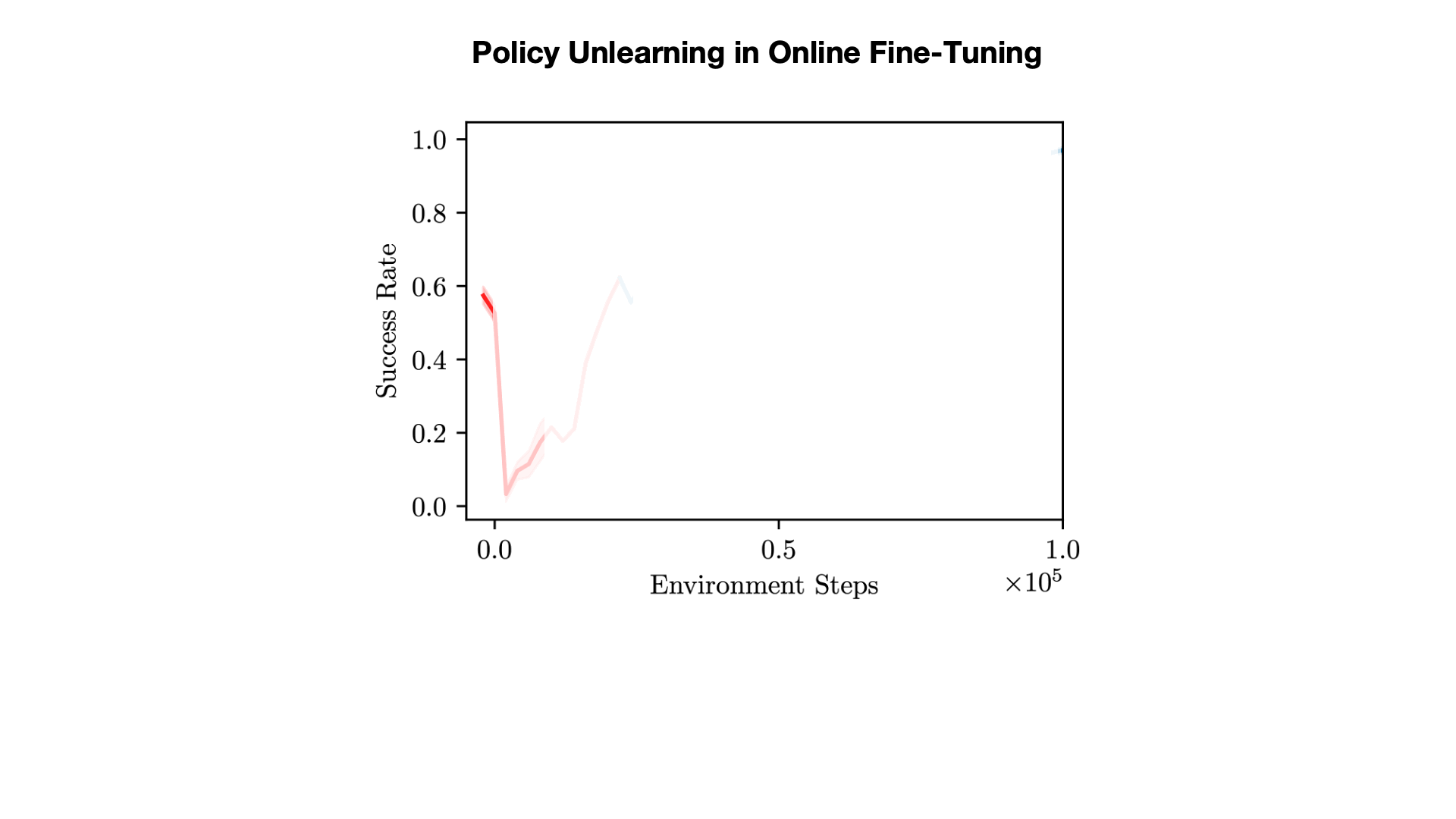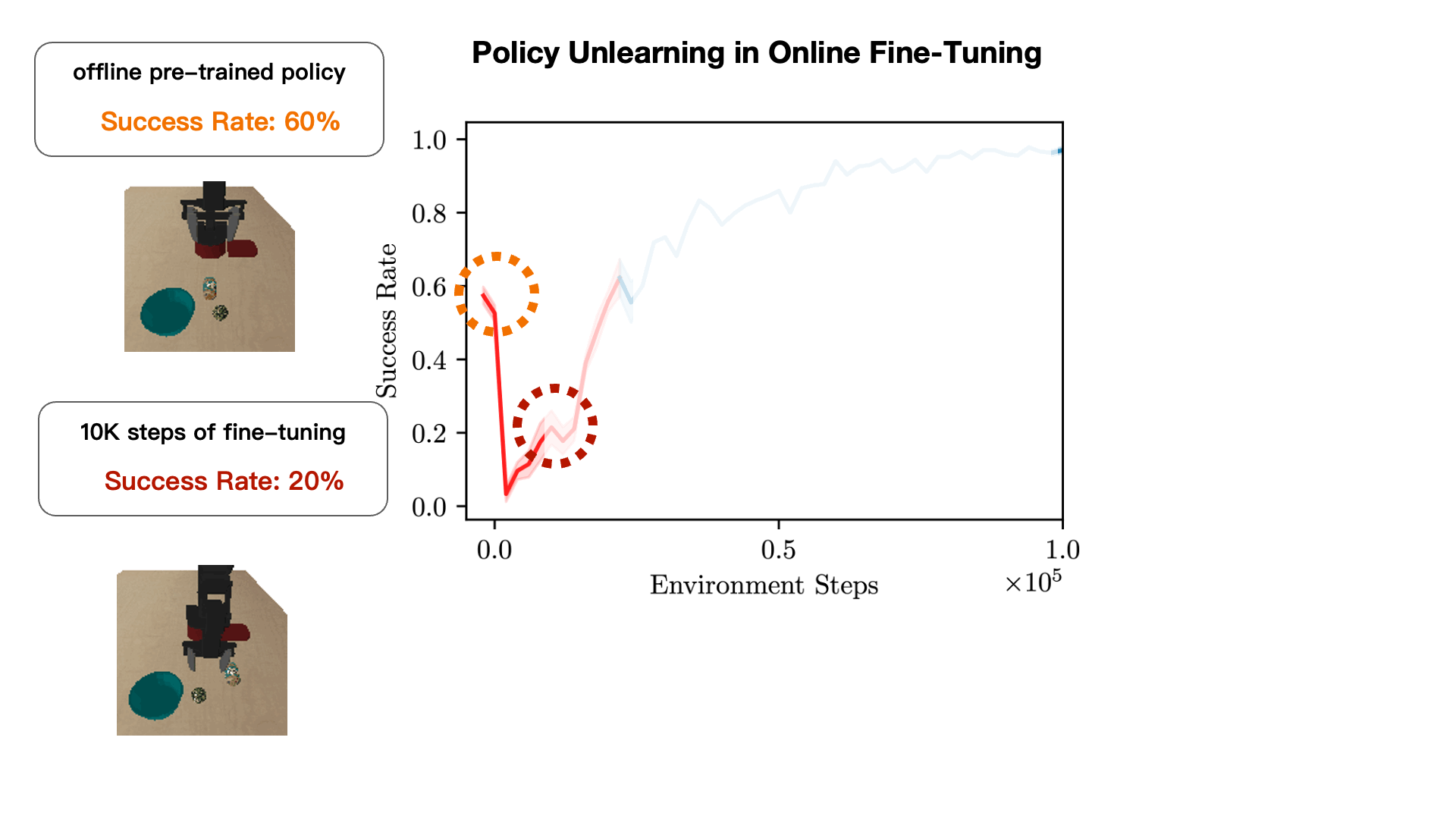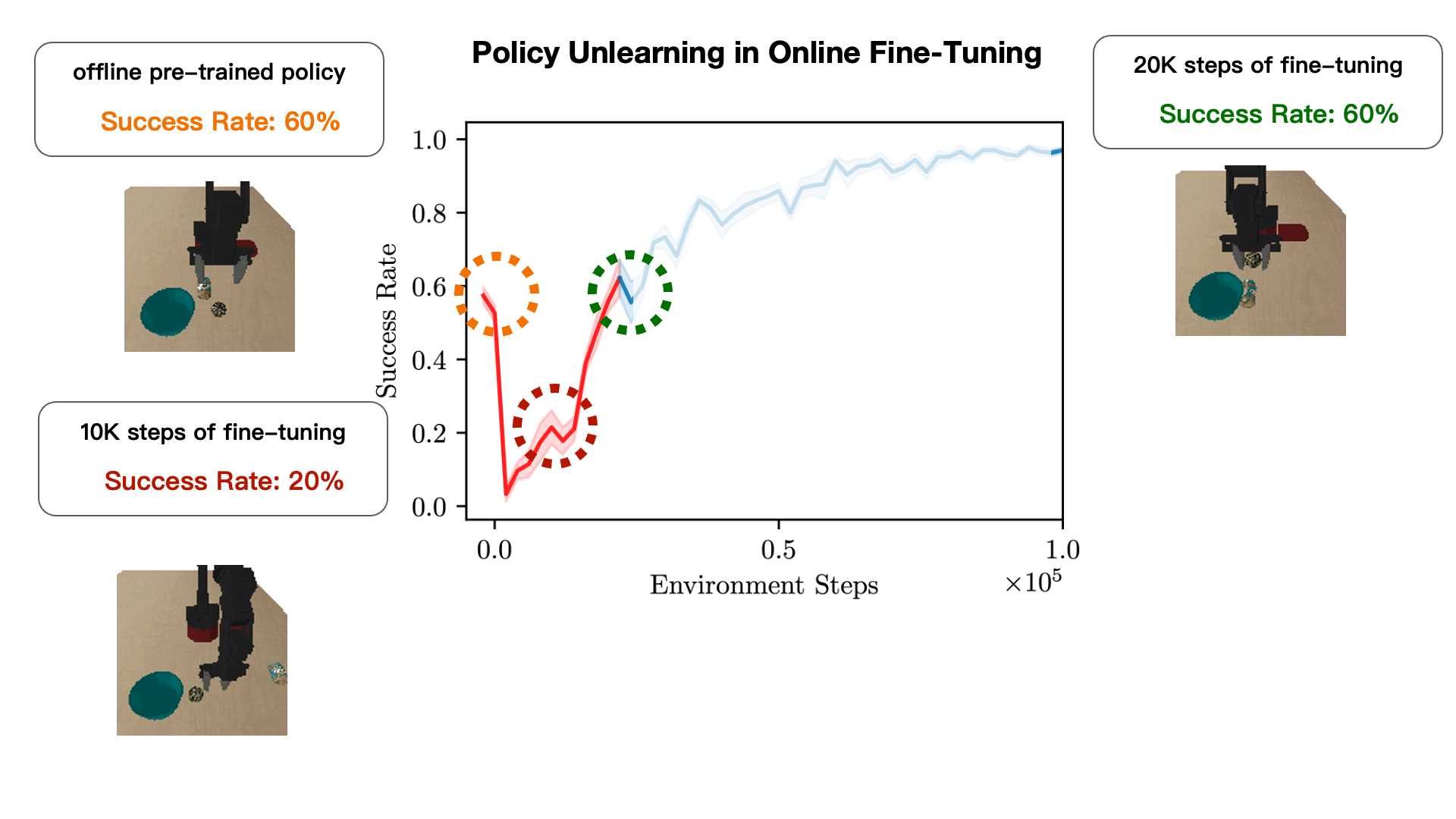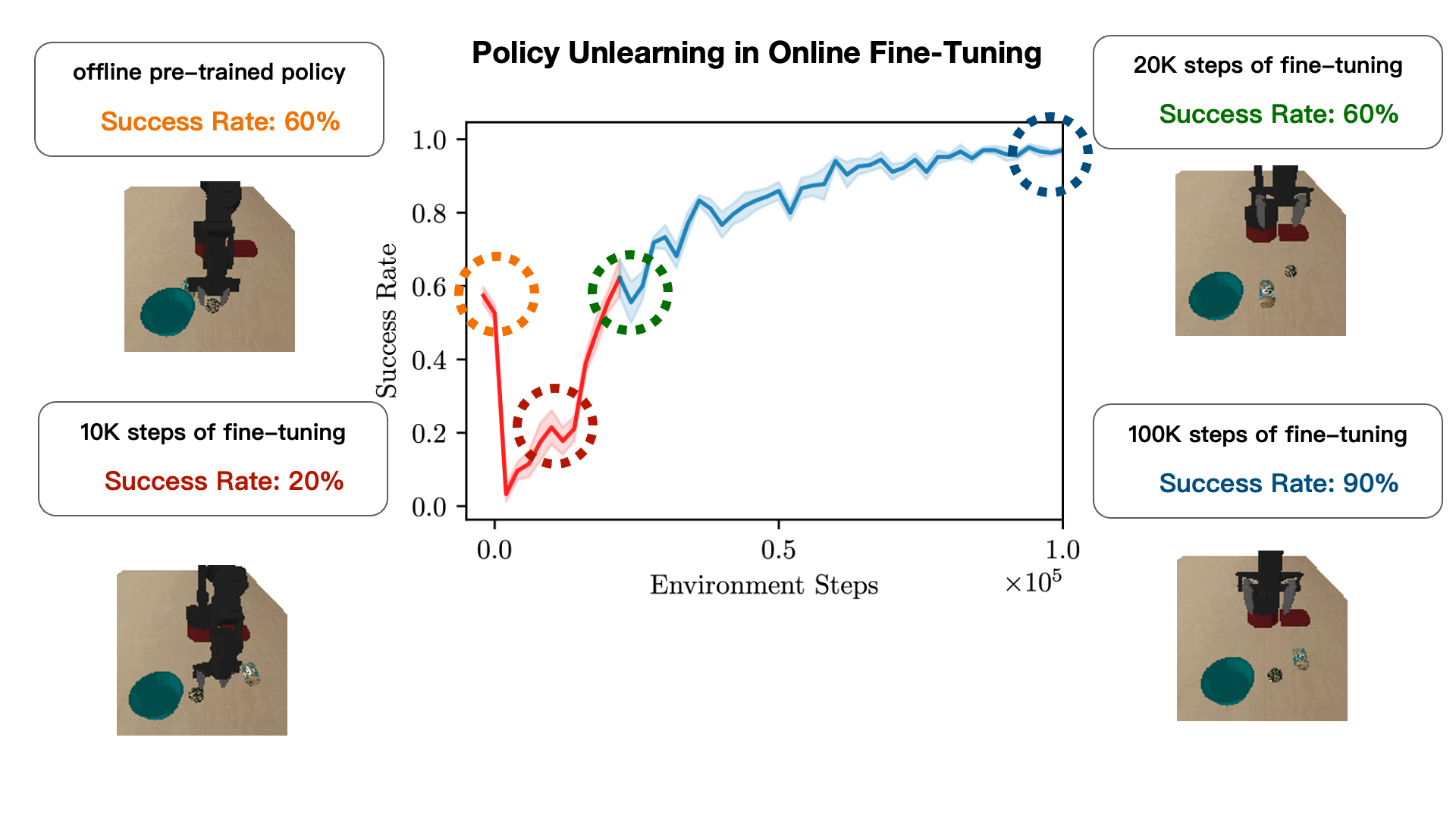
|
|
If we can ensure that the conservative value estimates learned using the offline data are calibrated, meaning that these estimates are on similar scales as the true return values, then we can avoid the unlearning phenomenon caused by conservative methods. We devise a method for ensuring that the learned values upper bound the true value of some reference policies whose values can be estimated more easily, (e.g., the behavior policy) while still lower bounding the value of the learned policy. In principle, our approach can utilize many different choices of reference policies, but for developing a practical method, we simply utilize the behavior policy as our reference policy. More concretely, we modify the CQL regularizer by masking out the push-down term of the learned Q-value on out-of-distribution actions only if the Q function is not calibrated. 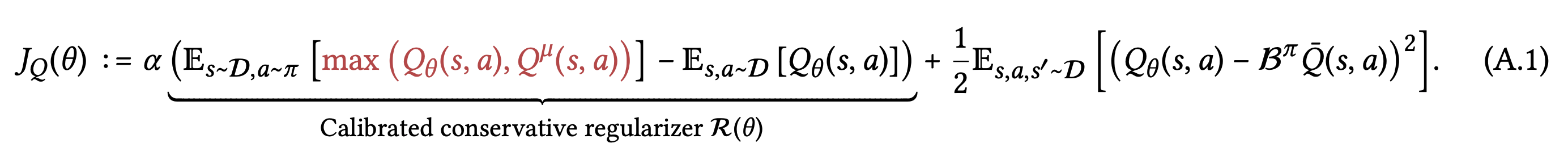
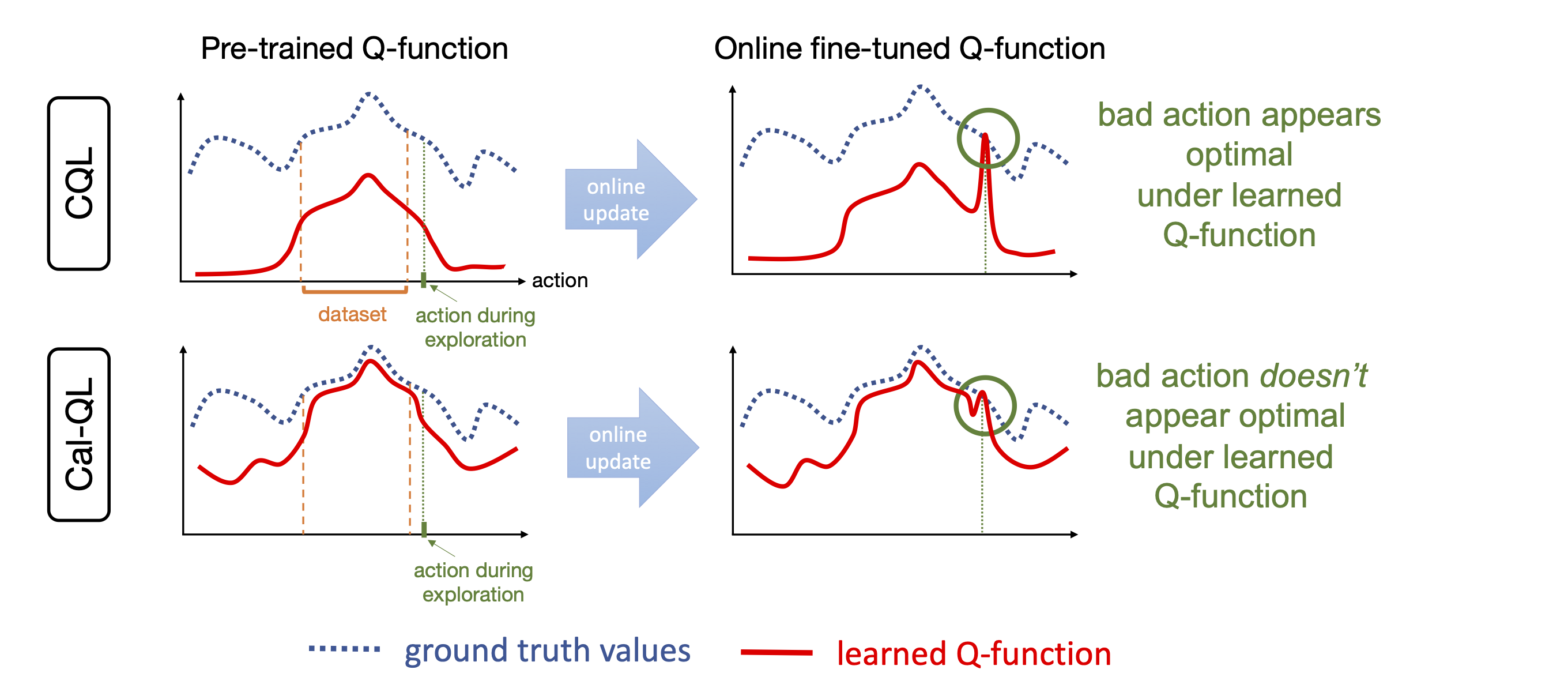
|
Cal-QL improves the offline initialization significantly.We evaluated our method and baselines on the Franka Kitchen, AntMaze, Adroit, and Visual Robotic Manipulation tasks. The plots show the online fine-tuning phase after pre-training for each method (except SAC-based approaches which are not pre-trained). Observe that Cal-QL consistently matches or exceeds the speed and final performance of the best prior method and is the only algorithm to do so across all tasks, achieving the best fine-tuned performance in 9 out of 11 tasks. Furthermore, the initial unlearning at the beginning of fine-tuning is greatly alleviated in all tasks. 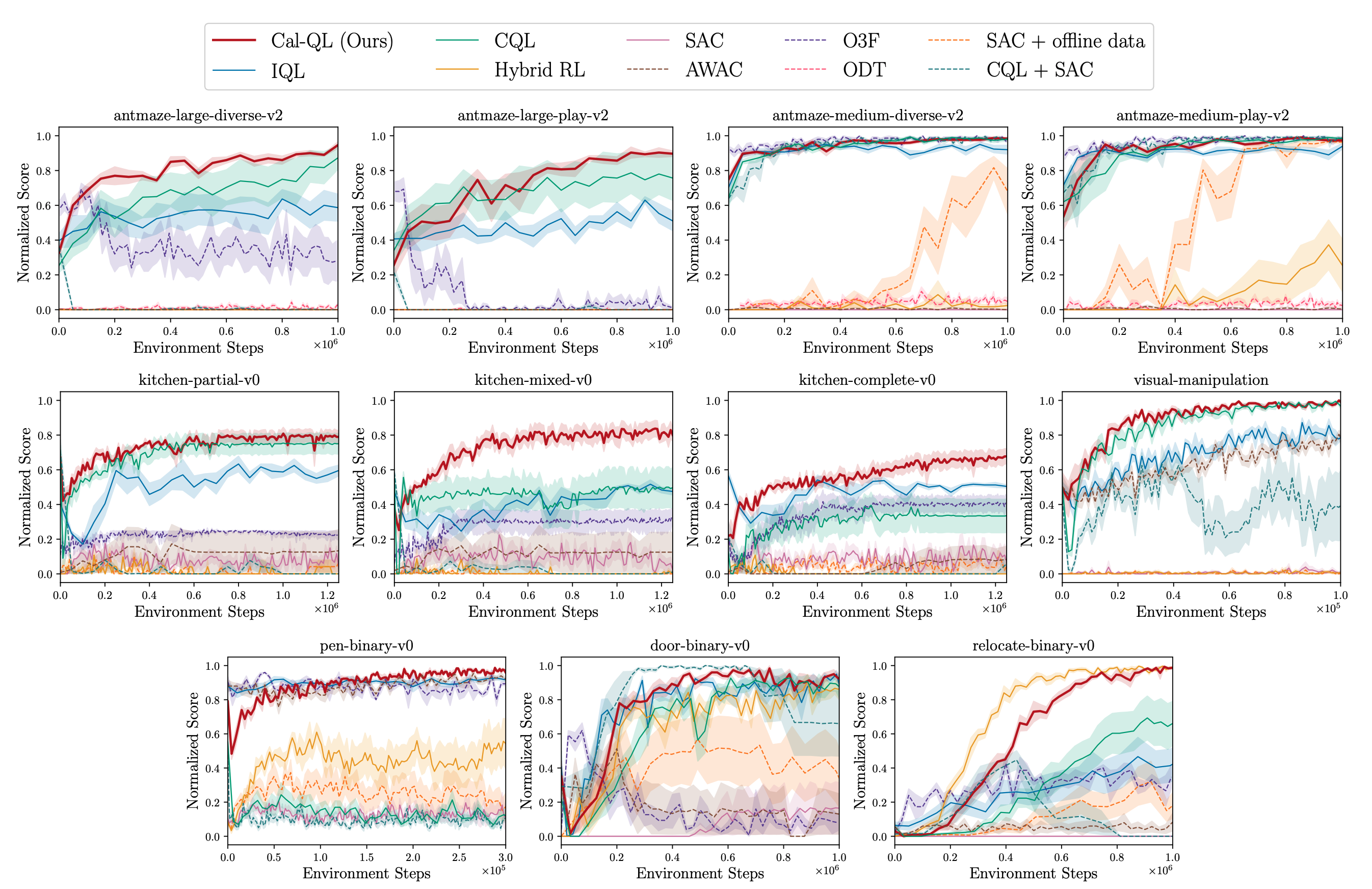
Cal-QL enables fast fine-tuning.We also evaluated the cumulative regret, averaged over the steps of online fine-tuning. This metric measures the speed of improvement during online fine-tuning, the smaller the better and 1.00 is the worst. Cal-QL attains the smallest overall regret, achieving the best performance among 8 / 11 tasks. 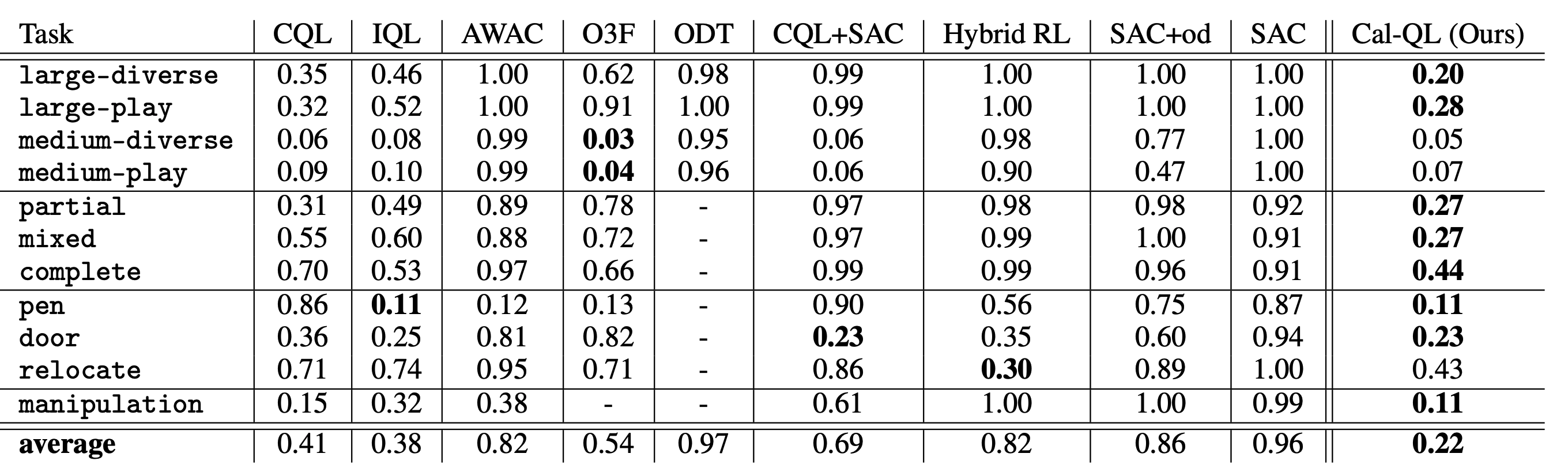
|
|
Check out other awesome work that leverages Cal-QL!
Pre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials by Kumar et al.
Robot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning by Yang et al.
Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance by Nakamoto et al.
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy by Chen et al. |
|
|